
Quick reminder what is frisor
Frisor is a web application in Python/Django which is just a box for interesting urls. When using untrusted network I don’t want to login anywhere to save interesting content I found. More about this is here: Introduction to frisor.
This week I introduced pagination in my urls table.
Frisor on github: firsor repo.
Currently pagination in my urls table in my application looks like this:
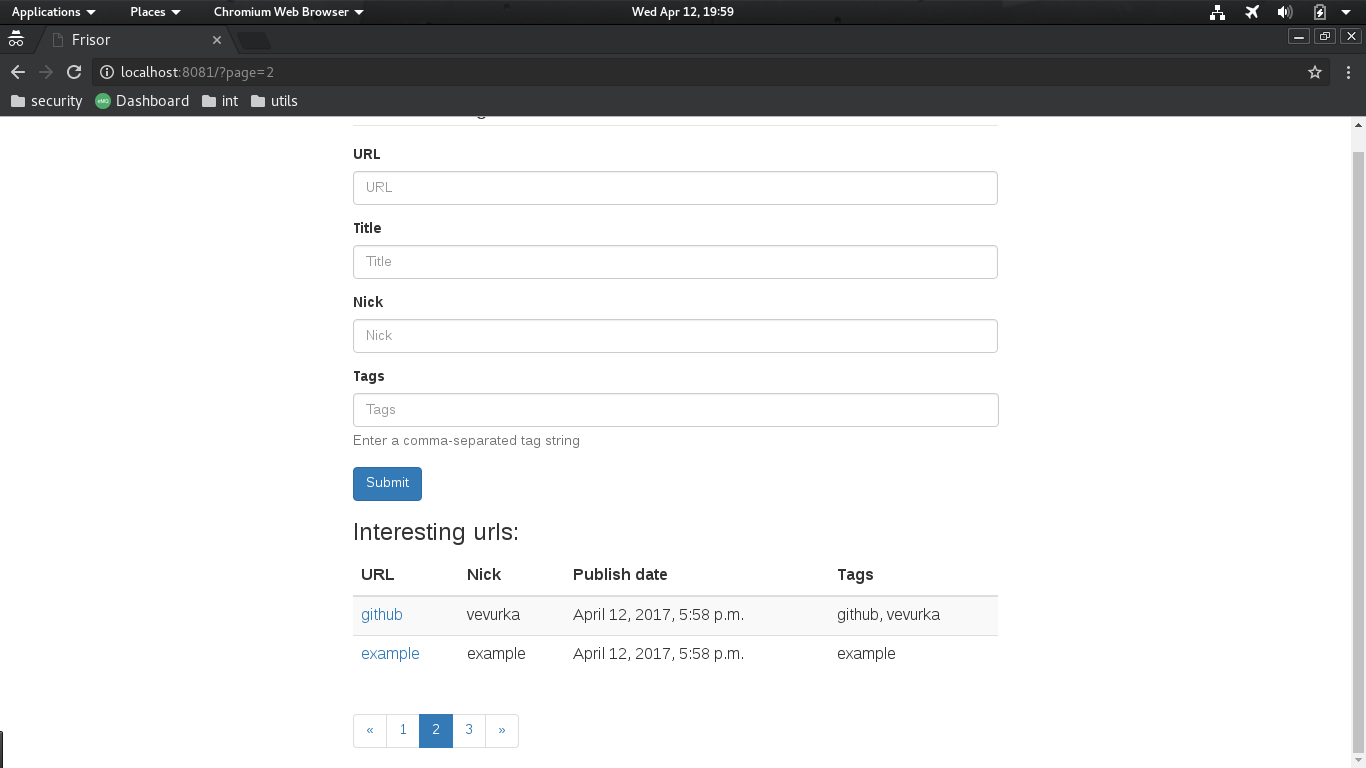
Pagination in Django
I was a bit surprised how easy was setting up a pagination in Django. For me it was enough to follow documentation - it worked with my first try!
The concept of pagination is quite easy - there is needed a structure which contains all data and can divide it into sublists with given length called pages.
Initializing pagination
In Django framework there is a django.core.paginator.Paginator which is responsible for managing pages - to
initialize it, you have to give it a number of elements which should be on a page
and a collection of data. It can be QuerySet, list or anything which has length (so implements __len__() method). For example:
p = Paginator(['string1', 'string2', 'string3'], 2)On the first page we will have ['string1', 'string2'] and on the second (and last) page we will have
['string3'].
The important thing here is that given data should have constant order, so it’s not a good idea to use for example a
set, because it’s not ordered.
There are two optional arguments which can be given to Paginator:
-
orphans- it doesn’t allow to have less than or equal given number elements on a last page, they are added to previous page -
allow_empty_first_page- it throwsEmptyPageexception when there are no elements
In case of orphans parameter set:
p = Paginator(['string1', 'string2', 'string3'], 2, orphans=1)we will have all three elements on the first page, because we don’t allow last page to contain less than or equal 1 element. So, basically we use it when we don’t want to have too less data on last page.
I wasn’t sure what happens if we set orphans to be bigger than length of our query set:
p = Paginator(['string1', 'string2', 'string3'], 2, orphans=4)but it happens that all elements are put to the first page in that case. It works that way even when we set:
p = Paginator(['string1', 'string2', 'string3'], 2,
orphans=4,
allow_empty_first_page=False)Authors of this library were quite thoughtful ![]() !
!
Ok, so we have an object which contains our paged data, what we can do with it?
Using pagination in a view
Paginator has only one method: page(number), which for a given number returns a list of elements (packaged
in a Page object) which should be on a page with that number or raises InvalidPage exception if it doesn’t exist.
So for:
paginator = Paginator(['string1', 'string2', 'string3'], 2)
page = paginator.page(1)
print(page.object_list)it will print ['string1', 'string2'].
So, now let’s use it in a view. Somehow we have to store information in a view about page we are currently at -
I think using parameter page in GET request is the best option here.
# views.py
class UrlView(FormView):
# ...
def get_context_data(self, **kwargs):
context = super().get_context_data()
# ordered collection:
url_list = Url.objects.order_by('-publish_date').all()
paginator = Paginator(url_list, self.number_of_items)
page = self.request.GET.get('page') # stored page number
# get list of urls which should be on page:
try:
url_list = paginator.page(page)
except PageNotAnInteger: # invalid page number, f.e not a number
url_list = paginator.page(1)
except EmptyPage: # not existing page number
url_list = paginator.page(paginator.num_pages)
context['url_list'] = url_list
return contextSo now, instead of putting whole url_list in response context I put trimmed collection. I could see one issue with code
above: all urls from database are taken every request, but that’s not true. According to
documentation Url.objects.all() (Url is a model)
returns a QuerySet which is lazy evaluated, so it takes only the data which is needed. The second thing here is
that QuerySet caches its results, so it doesn’t have to evaluate query every time.
Pagination in templates
To manage pagination in templates, we have to use django.core.paginator.Page (do you remember? It packages list of
objects we want to paginate - it’s returned by django.core.paginator.Paginator.page method)
attributes like:
-
has_previousto check if we can access to page withprevious_page_number -
has_nextto check if we can access to page withnext_page_number -
numberto get current page number -
paginator.num_pagesto get paginator object associated with page, which contains information about number of all pages
So our template can look like this:
<!-- index.html -->
<div class="pagination">
<span class="step-links">
{% if url_list.has_previous %}
<a href="?page={{ url_list.previous_page_number }}">previous</a>
{% endif %}
<span class="current">
Page {{ url_list.number }} of {{ url_list.paginator.num_pages }}.
</span>
{% if url_list.has_next %}
<a href="?page={{ url_list.next_page_number }}">next</a>
{% endif %}
</span>
</div>It will show not styled clickable paginator in which we can navigate to get to next and previous page.
It uses page parameter in href attribute of navigation link.
If we use django-bootstrap it’s more simple, just use bootstrap_pagination tag:
{% bootstrap_pagination url_list %} Some thoughts
Pagination isn’t so hard to design it, but they did a good job in Django, so it was not necessary to implement it
by my own. I’m quite happy that in django-bootstrap there is builtin tag for it, so I had to do almost nothing.
Next week I’m going to introduce some filtering to my urls table.
Any comments?



Leave a Comment